
こんにちは、弓仲研究室で画像生成モデルの学習・評価・応用に関する研究を行っているB4の野口翔伍です。本記事では、主に弓仲研をエントリー候補に考えている学部1〜3年生の方向けに、簡単に私の研究目的や研究環境等について書きます。研究環境は弓仲研の大事なアピールポイントの1つだと思いますので、経験談を細かく書きます。
目次:
1.研究目的
2.研究環境等
3.結論
1.研究目的
本研究では、自動運転ドメインの機械学習用のデータを、画像に付けられたアノテーション(正解ラベル)を保ちながらスタイル変換することで、画像とアノテーションをセットで”水増し”する手法の提案を目的としています。
従来の画像処理的な水増し(幾何的変換等)は、未だに深層学習分野でも広く使用されており、有効な手段です。しかし、スタイルの多様性が増えないのでこれに頼りすぎるとモデルが過学習(overfitting)してしまい、汎化能力が低下します。
そこで、近年新たな試みとして、画像生成モデルで訓練データを増やす試みがあります。具体的には、我々の場合、何らかの軽量なモデルで元の画像の天候・時間帯を判断し、それを変えることによって画像を増やします(例:「晴れ✕昼を雪✕夜へ」)。以下の画像はその例です。

先程、スタイルの多様性を増やすために画像生成モデルを使うと書きましたが、生成結果が元の画像とあまりにも違う場合、同じアノテーションを使えなくなるので、その画像に対してまたアノテーションをし直す必要があります。それを回避するため、「元の画像の意味的な構造を詳細に保ちながら水増しする」必要があるのですが、ここが結構難しく、奥が深いところです。
具体的な工夫としては、元画像のRGBからCanny EdgeやDepth、semantic segmentation画像を推定し、それを”条件”として生成モデルが画像を作成できるようにしています。学習の過程でモデルがこれらの3条件に忠実に画像を作成することを覚えることで、「元の画像の意味を詳細に保ちながら水増しする」ことができると考えています。
以下は現在の成果の一部です。
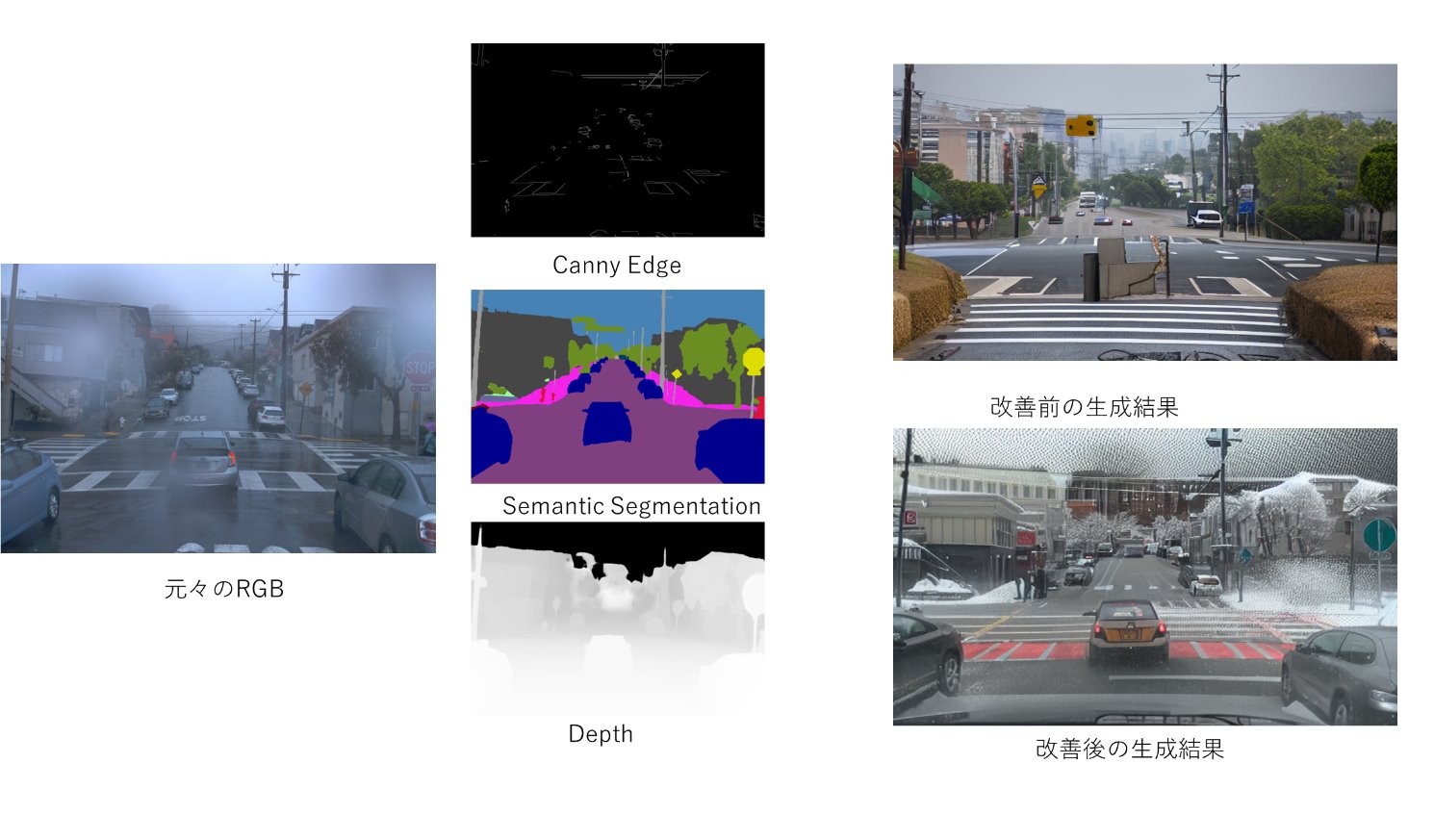
左端の雨の画像が既にアノテーションがついたRGBです。そこからCanny Edge, Semantic Segmentation, Depthを推定して、モデルを訓練します。訓練後のモデルは、訓練無しのモデルに比べて大幅に元々のRGBへの追従性が向上してることがわかります。雨から雪へ変化してるところから、「多様性を失わずに追従性を上げた」と言えます。
2.研究環境等
私は今年度で卒業し、群馬大学を出る予定ですので、私が使用してるPCの環境を誰かが引き継ぐことになる可能性が、かなり高いと思います。引き継がれる方はこの記事を見ると参考になるかもしれないです。
2.1 GPU
本研究では、画像生成モデルとして34層のU-Netと、それとは別に条件付与のための13層のCNNを使用しており、学習の軽量化の観点からU-NetはStableDiffusion 1.5の重みで初期化して凍結し、学習対象は13層のCNNのみとしています。学習対象が13層のCNNのみであっても、モデルの学習は膨大な演算処理を必要としますので、以下の VRAM 32GB 搭載の高価な GPU を使わせていただいています。

※VRAMが大きいほど、より大規模なモデルを扱えます。
https://www.nvidia.com/ja-jp/geforce/graphics-cards/50-series/rtx-5090/
※ただし、最近は流通量が減って値上がりが懸念されており、希望小売価格での購入が難しくなるかもしれません。
弓仲研配属当初はこのGPUはなく、手元にあるのはRTX3070というだいたい3.5万〜7.5万円のGPUで、VRAMが8GBしかないため、「画像生成モデルの訓練は厳しく、Deep Learning関連でやれることはだいぶ限られるな」と感じていました。そのため、やりたい研究と手元の事情を弓仲先生に相談した結果、すぐに新たなGPU付きPCの購入を提案していただき、相談からなんと1ヶ月経たない内に5090を研究室へ迎え入れることができました。
※コスパを考えると、RTX3070も用途によっては大変いいGPUだと思います。
2.2 SSD・他
本研究ではモデルの学習・評価時に大規模なデータセットを扱います。具体的には、訓練時は15万枚のRGBと、それぞれについて3種の条件マップ(Edge, Depth, semseg)を使うので、全体で60万枚程度の画像を訓練中使います。さらに、私の研究では画像を生成するので、モデルの重みや使い方をすこし変えるたびに、評価用として3千枚のデータが増えます。そこで、大きな容量のSSDが必要になりました。
※もっと言うとTEXT promptをTEXT Encoderに事前に通したり、RGB類はVAEに事前に通してベクトルとして保持することにより、SSDに負担をかける代わりに、学習時のGPU負担を軽減しています。そのため大きなSSDが要るのです。
元々、PCには2枚の4TB SSD(Windows)が入っていたのですが、研究でLinuxを使いたいことから、うち1枚はwindowsから削除し、Ubuntu(Linux系OS)を入れて使用することにしました。これによってUbuntuは使えるようになりましたが、Ubuntuからネイティブに使用できるSSDが1枚になってしまったので、大きな容量のSSDがもう一枚欲しくなりました。そこで、またまた弓仲先生にmeetingで相談し、以下の8TBのSSDを即決で追加購入していただきました。

https://semiconductor.samsung.com/jp/consumer-storage/internal-ssd/9100-pro/
※これの導入の際、PCに詳しい現M2の安達さんに非常にお世話になりました。
Linuxを使いたい理由は様々ありますが、主な理由は深層学習系論文で公開されてるソースコードが、ほとんどLinuxで動かすことを前提とされているからです。windowsからWSL2を使って仮想環境としてUbuntuを使用するという手もあります。ただし、深層学習の研究コードには C++ / CUDA のカスタムコンパイル(setup.py)が必要なものも多く、WSL2 だと「コンパイルは通るが、実行すると CUDA カーネルが落ちる」「環境は同じのはずなのに挙動が本家 Ubuntu と微妙に違う」といった状況が起きやすく、実際にWSL2 ではどうしても動かないコードがいくつかありました。
build_ext
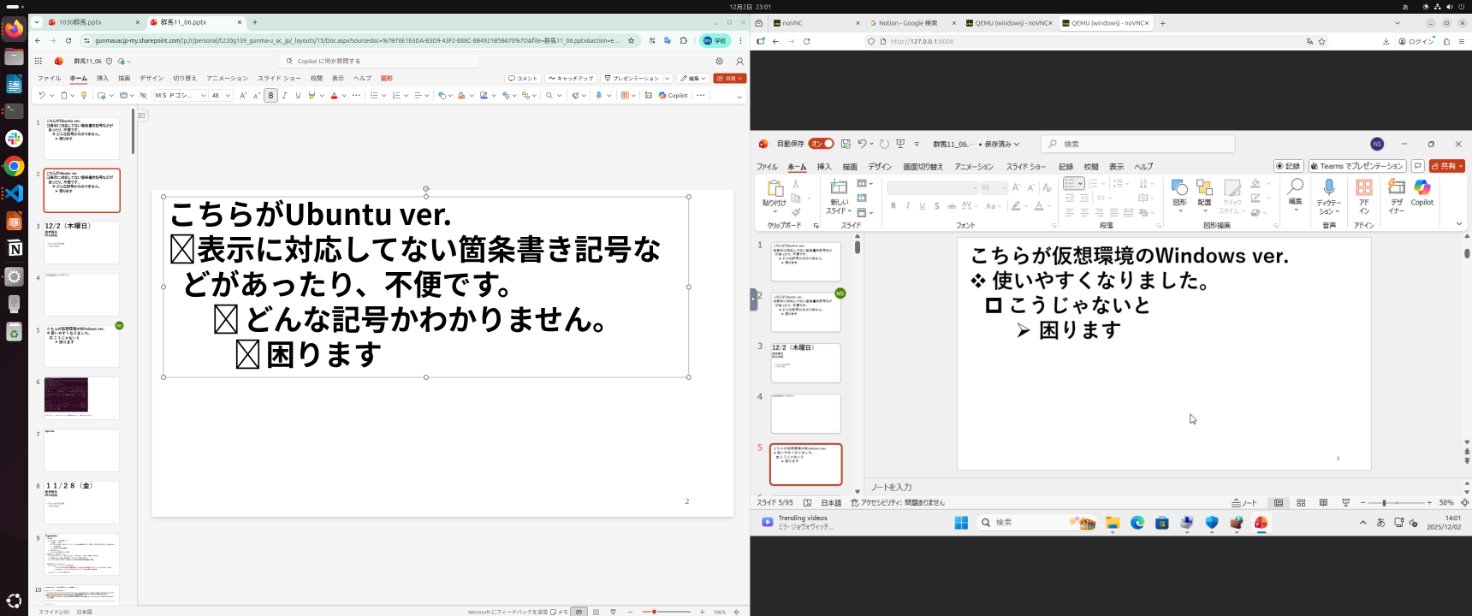
ただ、LinuxではOfficeが使えないため、LibreOfficeという互換ソフトを使うか、ブラウザ版のOfficeを普通は使う羽目になります。ただし個人的にどちらも少し使い勝手が悪く、LibreOfficeについては慣れないインターフェイスのため使いたくなく、ブラウザ版のOfficeはUbuntuから開くと特定の文字や記号で文字化けしたりして使いにくかったです。そのため、Ubuntu 上に「Windows を丸ごと仮想マシンとして動かし、そこに Office をインストールして、Ubuntu のアプリのように使う」という方法を取ってます。結果的に以下の画像のように、本来Web版だと文字化けする文字が、正常に表示されており、使えなかったフォントも使えるようになりました。結果的に今は、大容量のSSDとLinuxで開発はできるし、Officeでパワポやwordを書ける…といういい感じの環境を整えることができました。
3.結論
弓仲研究室では、回路・VR・AR等、様々なテーマが扱われていますが、深層学習にもきちんと取り組めます。また、深層学習で大事な計算資源なども、相談次第で快く導入していただけますし、PCのセッティングで困れば先輩や先生が優しく助けてくれます。なので結論として、誇張抜きでおすすめできる研究室だと思います。
以上。